Bedrock retrieve_and_generate API——KB検索と回答生成を1回で完結させる仕組み
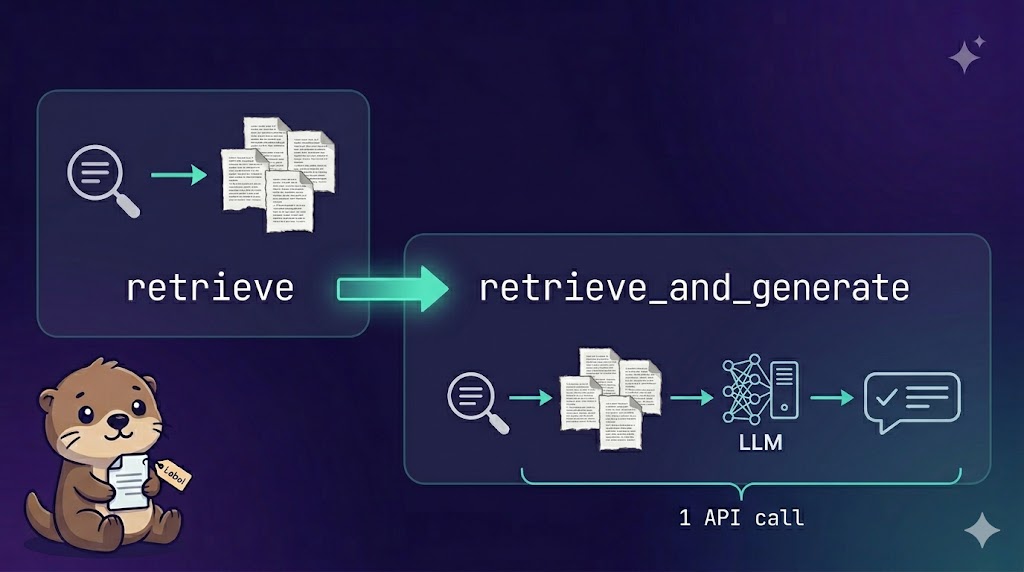
Bedrock Knowledge BaseのRAGを実装するとき、検索APIには retrieve と retrieve_and_generate の2種類がある。この記事ではその違いと、retrieve_and_generate のリクエスト・レスポンス構造を実装コードをベースに解説する。
対象はカスタムLambdaからKBを呼び出す構成に絞っている。Bedrockの全体アーキテクチャよりも「実際に書くコードの構造」にフォーカスした記事。
retrieve と retrieve_and_generate の違い
| API | 動作 |
|---|---|
retrieve |
KB検索のみ。関連ドキュメントの断片を返す |
retrieve_and_generate |
KB検索 + LLMによる回答生成を1回で完結 |
retrieve を使う場合、返ってきたドキュメント断片を自分でプロンプトに組み込んでLLMを呼び出す処理が別途必要になる。retrieve_and_generate はその2ステップをまとめて実行してくれるため、シンプルなRAGであればこちらを使うほうが実装コストが低い。
今回のカスタムLambdaでは retrieve_and_generate を採用している。
クライアントは bedrock-agent-runtime
retrieve_and_generate は bedrock-agent-runtime クライアントを使う。bedrock-runtime(モデルを直接呼ぶAPI)とは別物なので注意。
import boto3
# bedrock-runtime ではなく bedrock-agent-runtime
client = boto3.client("bedrock-agent-runtime", region_name="ap-northeast-1")
| クライアント | 主なAPI | 用途 |
|---|---|---|
bedrock-runtime |
invoke_model |
モデルを直接呼ぶ |
bedrock-agent-runtime |
retrieve / retrieve_and_generate / invoke_agent |
KB・エージェントなどBedrockの上位レイヤーを使う |
名前に agent が入っているが、エージェント専用ではなくKnowledge Baseの操作もこちらのクライアントを使う。
リクエスト構造
retrieve_and_generate のリクエストは以下の構造。
response = client.retrieve_and_generate(
input={"text": query}, # ユーザーの質問
retrieveAndGenerateConfiguration={
"type": "KNOWLEDGE_BASE",
"knowledgeBaseConfiguration": {
"knowledgeBaseId": knowledge_base_id, # KBのID
"modelArn": model_arn, # 回答生成に使うモデル
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"numberOfResults": 5, # 検索で取得するドキュメント数
"filter": { ... }, # メタデータフィルター(任意)
}
},
},
},
)
modelArn はリクエスト時に都度指定する
KBの設定画面にも「モデルを選ぶ」箇所があるため混乱しやすいが、役割が異なる。
| モデル | 役割 | 設定場所 |
|---|---|---|
| 埋め込みモデル(Titan など) | ドキュメントをベクトル化してインデックスを作る | KBの設定 |
| 生成モデル(Claude など) | 検索結果をもとに回答文を生成する | APIリクエスト時に指定 |
retrieve_and_generate は「KB検索」と「回答生成」を1回のAPIで行う設計のため、「どのモデルで生成するか」をリクエストのたびに指定する必要がある。
modelArnの書き方:
region = "ap-northeast-1"
model_arn = f"arn:aws:bedrock:{region}::foundation-model/anthropic.claude-3-haiku-20240307-v1:0"
レスポンスの読み方
レスポンスには回答文と引用元(citations)が含まれる。
answer = response["output"]["text"] # LLMが生成した回答文
citations = []
for citation in response.get("citations", []):
for ref in citation.get("retrievedReferences", []):
citations.append({
"text": ref.get("content", {}).get("text", ""), # 参照したドキュメントの断片
"location": ref.get("location", {}), # S3のロケーション情報
})
citations の役割
citationsには「この回答はどのドキュメントのどの部分を根拠にしているか」が入っている。
{
"text": "接待費は1人あたり1万円を上限とする",
"location": {
"type": "S3",
"s3Location": {
"uri": "s3://your-bucket/documents/営業部/営業部_規程.txt"
}
}
}
citations が空の場合、フィルター条件に合うドキュメントが見つからなかったことを意味する。回答文の内容はモデルによって変わるため、「ドキュメントが見つかったか」の判定はcitationsの件数で行うのが確実。
if not citations:
# 該当ドキュメントなし
...
ハマりポイント
クロスリージョン推論プロファイルは閉域で使えない
modelArnにクロスリージョン推論プロファイル(apac. プレフィックス)を指定すると、閉域VPC内では ValidationException が発生する。
# NG: クロスリージョン推論プロファイル
model_arn = "arn:aws:bedrock:ap-northeast-1::foundation-model/apac.anthropic.claude-3-haiku..."
# OK: 同一リージョンのモデルARNを直接指定
model_arn = "arn:aws:bedrock:ap-northeast-1::foundation-model/anthropic.claude-3-haiku-20240307-v1:0"
クロスリージョン推論プロファイルは複数リージョンにリクエストをルーティングする仕組みのため、他リージョンへのアウトバウンド通信ができない閉域VPCでは使用不可。GenU標準のLambdaはこのプロファイルを使っていないため発生しないが、カスタムLambdaを新規実装する際に誤ったARNを書くと踏む。
IAMポリシーに3つのアクションが必要
Lambdaの実行ロールに以下を付与する。bedrock:InvokeModel を忘れがち。
{
"Action": [
"bedrock:RetrieveAndGenerate",
"bedrock:Retrieve",
"bedrock:InvokeModel"
],
"Resource": "*"
}
まとめ
| ポイント | 内容 |
|---|---|
| クライアント | bedrock-agent-runtime(bedrock-runtime ではない) |
| modelArn | KBの埋め込みモデルとは別。リクエスト時に生成モデルを指定 |
| クロスリージョンARN | 閉域VPCでは使用不可。同一リージョンのARNを直接指定 |
| 0件判定 | citationsの件数で判定する |