Intel MacにローカルLLMを入れてみたら思ったより遅かった話
ローカルLLMを試してみたかった。
プライバシーが守られる、オフラインで動く、APIコストがかからない。メリットはわかっている。あとは動かすだけ。
手元にあったのは2020年のIntel MacBook Pro。これにOllamaとGemma3を入れてみた。
検証環境
| 項目 | 内容 |
|---|---|
| 機種 | MacBook Pro 2020 |
| CPU | Intel Core i5 2GHz(4コア) |
| メモリ | 16GB |
| OS | macOS Monterey 12.7.6 |
| 操作方法 | VSCode Remote SSH 経由 |
Ollamaとは
Ollamaはローカル環境でLLMを動かすためのツール。モデルの管理、サーバー起動、APIの提供を一括でやってくれる。
ollama run gemma3:4b の一行でGemma3が動く。セットアップの手軽さがウリ。
インストール手順
1. Homebrewでインストール
brew install ollama
ここが一番時間がかかる。OllamaはHomebrewでインストールする際、cmakeとgoをソースからビルドする。
Intel MacBook Pro(i5 2GHz)では 約40分 かかった。完了するまでそのまま待つしかない。
2. Ollamaを起動
ollama serve
Listening on 127.0.0.1:11434 と表示されれば起動完了。このターミナルは開いたままにしておく。
3. Gemma3を取得
別のターミナルタブで実行する。
ollama pull gemma3:4b
約3.3GBのモデルファイルがダウンロードされる。success と表示されれば完了。
4. 実行
ollama run gemma3:4b
>>> プロンプトが出たら話しかけられる。
実際に動かしてみた
まず速度を計測するために /set verbose モードをオンにした。
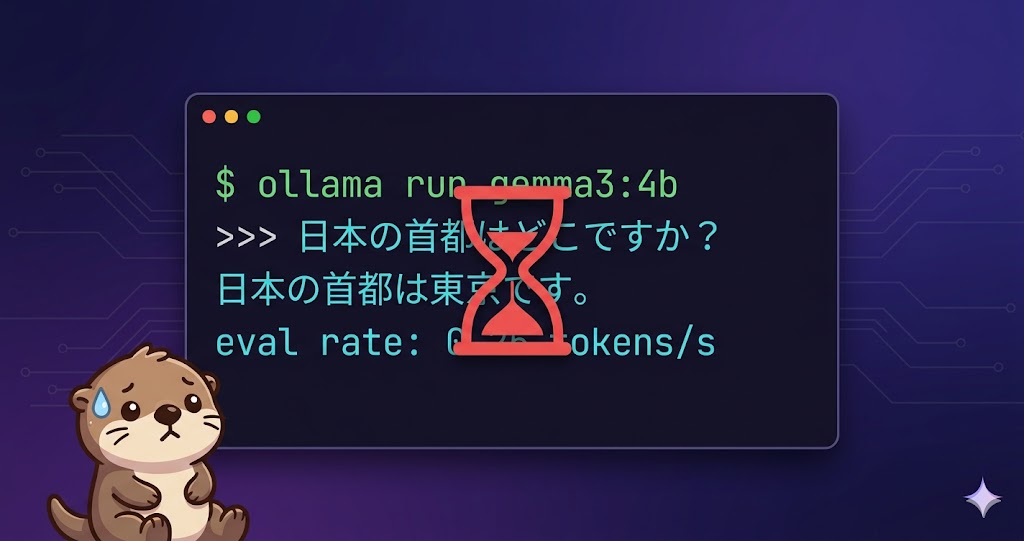
>>> /set verbose
Set 'verbose' mode.
>>> 日本の首都はどこですか?
日本の首都は東京です。
total duration: 2m57.601379686s
load duration: 40.881221702s
prompt eval count: 157 token(s)
prompt eval rate: 1.45 tokens/s
eval count: 7 token(s)
eval duration: 27.925542952s
eval rate: 0.25 tokens/s
計測結果
| 指標 | 結果 |
|---|---|
| モデル読み込み時間 | 40.8秒 |
| プロンプト処理速度 | 1.45 tokens/sec |
| 回答生成速度 | 0.25 tokens/sec |
| 合計時間 | 2分57秒 |
| 回答内容 | 日本の首都は東京です。(7トークン) |
7トークンの回答を生成するのに28秒かかった。1トークン出るのに約4秒。
会話として使うにはかなり厳しい速度。
なぜ遅いのか
Intel MacではGPUオフロードが効かない。CPUだけで推論するため、どうしても遅くなる。
AppleシリコンのMacはCPUとGPUがメモリを共有するユニファイドメモリ構造で、Ollamaがそれを活用できる。Intel Macにはこの仕組みがない。
4コアCPUで計算するのと、GPUの数千コアで並列計算するのでは、速度が桁違いになる。
本格的に使うなら何が必要か
動くことは動く。ただし実用速度ではない。本格的に使うなら以下のいずれかが必要になる。
Appleシリコン Mac(M1以降)
ユニファイドメモリにより、RAM全量をモデルの推論に使える。M4 16GBモデルで30〜50 tokens/sec程度が期待できる。
NVIDIA GPU搭載のWindows / Linux
VRAMの量が性能を決める。RTX 4060(8GB)で40〜60 tokens/sec程度。VRAMが多いほど大きいモデルを動かせる。
クラウド / API
ローカルにこだわらないならAPIを使う方が現実的。品質・速度ともにローカルより高く、初期投資も不要。
まとめ
- Intel MacでもOllamaは動く
- ただし回答生成速度は 0.25 tokens/sec(実用は難しい)
brew install ollamaのビルドに40分かかる- 本格利用にはAppleシリコンかNVIDIA GPUが必要
- まず試してみたいだけなら今の環境でも十分
「ローカルLLMって実際どうなの?」を体験するには十分だった。速さを求めるなら環境を選ぶ必要がある。